

By Fabien – Partie 2
Dans le premier article, nous avons exploré ce qu’est une Modern Data Stack (MDS), ses grands principes, ses piliers structurants (modularité, gouvernance, accessibilité, etc.) et la manière dont elle transforme la relation des entreprises à la donnée.
Dans ce second volet, place au concret.
Nous allons plonger au cœur de l’architecture d’une MDS et détailler ses composants techniques : les couches successives de traitement, les moteurs de calcul, les formats de stockage, les outils d’orchestration, ou encore les choix technologiques à faire.
Car au-delà du concept, une MDS repose sur des briques bien réelles… qu’il faut savoir choisir et articuler.
L’architecture d’une Modern Data Stack
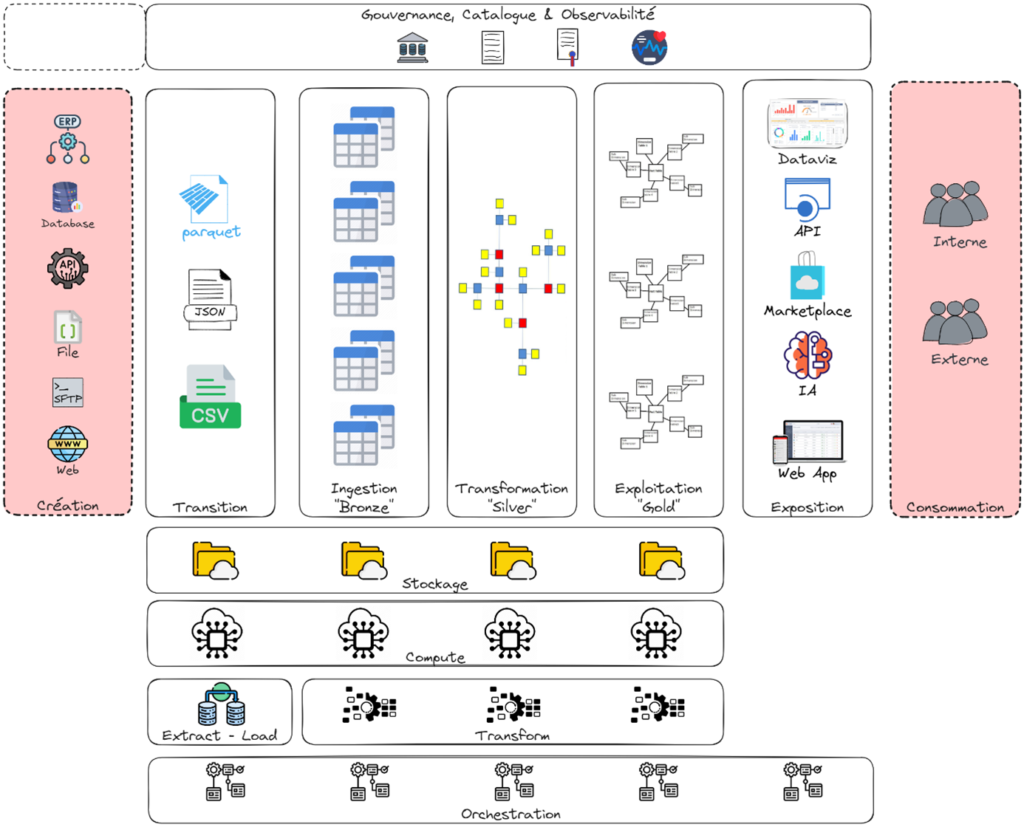
Ce schéma est bien connu, mais le processus de gestion des données n’a pas fondamentalement changé ; ce qui évolue, ce sont les outils permettant de transformer la donnée brute en donnée raffinée.
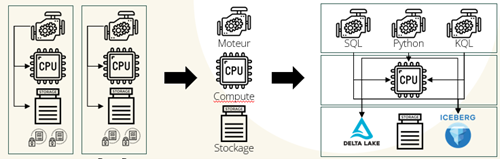
Avec les progrès technologiques, ce qui a véritablement changé, c’est le découplage des trois éléments clés d’une base de données : la puissance de calcul (CPU et mémoire), le moteur de calcul et le stockage (formats de fichiers propriétaires et logs). Autrefois, ces éléments étaient regroupés dans des bases de données telles que Microsoft SQL, Oracle ou Teradata. Aujourd’hui, la Modern Data Stack applique ce même principe en séparant ces composants, tout en utilisant des formats de fichiers ouverts et en mutualisant les ressources.
Les différentes couches
1. La couche de Transition (aka landing zone)
Cette première couche est utilisée pour stocker provisoirement des fichiers avant d’être ingérés. Ils peuvent provenir de différentes sources comme un SFTP ou d’un file system ; voire ce SFTP ou fileshare peut être considéré comme la couche de transition. Dans certains cas, elle peut ne pas être utilisée.
Il ne s’agit en aucun cas d’une zone d’archivage. Il est possible d’inclure un archivage des fichiers traités, mais dans ce cas, un espace spécifique sera utilisé. Les fichiers seront compressés avant l’archivage.
Un premier data contract apparaît afin de convenir entre le data provider et la data team d’au minimum le format, la structure des données reçues et la périodicité.
2. La couche d’Ingestion (aka Bronze, ODS)
Dans cette couche sont conservées les données brutes (raw data) avec une profondeur d’historique qui peut être différente de la profondeur du système source. Aucune transformation n’est apportée, on peut voir cette couche comme une copie parfaite des données sources. À partir de cette couche, les données sont stockées dans un format de fichier ouvert de type Delta Lake, Iceberg ou Hudi.
Comme pour la couche de transition, une organisation par source de données est mise en place. Il faudra (si possible) conserver le pattern du nom de fichier ou de table de la source. Un champ de type TIMESTAMP sera ajouté afin de stocker la date de chargement, ce qui permettra de connaître la fraîcheur (freshness) des données.
3. La couche de Transformation (aka Silver, Argent, Dwh)
À partir de cette couche, les données sont structurées en utilisant un type de modélisation spécifique à l’analytique : Kimball, Inmon ou Data Vault. La modélisation devra faire totalement abstraction de la structure des sources, mais s’articulera autour de notions d’objets métier qui sont plus parlants pour les utilisateurs non techniques. De plus, elle permet d’agréger différentes sources pour le même objet métier, de gérer un suivi des mises à jour de par sa normalisation et permet à différents domaines métiers de travailler en parallèle.
La problématique de la multitude de tables, et donc de la multitude de pipelines de chargement, est atténuée par l’automatisation de la génération des tables et des flux : la structuration étant très normée, on répète constamment les mêmes procédures ; seul le mapping des données change.
C’est à partir de cette couche que « l’intelligence » humaine intervient afin de définir les différents objets métiers, leurs attributs, les liens existants entre ces objets. Ce travail demande une collaboration étroite entre les sachants métiers, les sachants côté solutions et la data team. C’est un nœud où la documentation (mapping de données, définition des termes, …) a une importance forte.
4. La couche d’Exploitation (aka Gold, Or, Datamart, semantic layer)
Dans cette couche, les données sont mises en qualité, agrégées, répondent à des besoins spécifiques des métiers. Elles alimentent les différents moyens de les consommer de la couche suivante.
À ce niveau, la modélisation des datasets se fait en étoile (snowflake de Inmon/Kimball) afin d’être facilement utilisables par les systèmes. Le format de mise à disposition peut varier en fonction des use cases. C’est sûrement la couche la plus critique pour la data team, car elle devient la référence des données / KPI au sein de l’organisation et est attentivement scrutée par tous les utilisateurs.
À ce niveau, un data contract très important en termes de gouvernance et de transparence est mis en place afin de définir finement les données mises à disposition.
5. La couche d’Exposition
À la différence des couches précédentes, cette dernière n’est pas une couche de stockage des données. Elle sert à mettre à disposition les données ou datasets sous différents moyens : dashboarding, API, data marketplace, data sharing, …
Le stockage

Les datalakes ont révolutionné la façon dont les sociétés gèrent les données. Traditionnellement, les données étaient stockées dans des bases de données structurées, ce qui rendait difficile la gestion des données non structurées ou semi-structurées. Les datalakes, quant à eux, offrent une solution flexible et évolutive.
Ils permettent aux sociétés de stocker de grandes quantités de données brutes, permettant ainsi des analyses avancées, un apprentissage automatique et une prise de décision basée sur les données. Dans le monde de la data, on entend dorénavant plus le nom de lakehouse que de datalake.
Apache Iceberg vs Delta Lake vs Apache Hudi
Quel format de table ouvert choisir ? Au cours de l’année 2024 il y a eu beaucoup de mouvements autour de ces formats et Iceberg semble prendre une avance sur Delta alors que Hudi reste en retrait.
Delta Lake
Développé par Databricks, il est conçu pour améliorer l’efficacité et la fiabilité du stockage des données, en particulier dans le traitement des grands volumes de données utilisant Spark. Il est possible d’interroger ce format au travers de databases en SQL ou avec le langage Python.
Caractéristiques clés
- Transactions ACID : Delta Lake assure l’atomicité, la cohérence, l’isolation et la durabilité (ACID) dans les transactions de données.
- Scalabilité et performance : Conçu pour la scalabilité, Delta Lake traite efficacement de grands volumes de données avec des performances optimisées.
- Contrôle de schéma : Il impose un schéma lors de l’écriture, assurant l’intégrité et la cohérence des données.
- Time Travel : Delta Lake permet aux data engineers d’accéder aux versions précédentes des données, permettant une meilleure gestion et audit des données.
Apache Iceberg
Développé par Netflix et maintenant porté par la communauté Apache, il offre une performance et une fiabilité améliorées pour l’accès aux données à grande échelle et est compatible avec plusieurs moteurs de traitement de données. Tout comme le format Delta Lake il est possible d’interroger ces fichiers au travers de database en SQL ou avec le langage Python.
Caractéristiques clés
- Partitionnement caché : Iceberg abstrait la complexité du partitionnement pour l’utilisateur, le gérant plus efficacement sous le capot.
- Versioning et retour en arrière : Il prend en charge le versioning basé sur des instantanés, permettant des retours en arrière faciles et des analyses de données historiques.
- Évolution du schéma : Iceberg prend en charge l’ajout, la suppression et la mise à jour du schéma de la table sans affecter les données existantes.
- Agnostique au format de fichier : Il peut fonctionner avec divers formats de fichiers comme Parquet, ORC et Avro.
Choix cornélien
Chacun des deux formats présente ses avantages et inconvénients :
Iceberg est reconnu pour les traitements analytics, mais Delta serait plus performant pour la gestion des pipelines ELT.
Iceberg est le format adopté par Snowflake (qui est un partenaire) et Delta est le format adopté par Microsoft Fabric (game changer dans le monde de l’analytics). En clair, pas de choix arrêté, et encore moins depuis le Data Summit & IA 2024, où trois grandes annonces ont été faites : un rapprochement capitalistique et technique a été annoncé entre Delta et Iceberg, Microsoft Fabric prend en charge nativement Snowflake, et le projet XTable pour unifier les métadonnées de Iceberg et Delta est en cours.
Le compute (moteur de calcul)
Le(s) moteur(s) de calcul devront avoir la capacité de traiter à grande (voire très grande) vitesse les données stockées. De plus, au minimum, les langages SQL et Python devront être interprétés par le(s) moteur(s) de calcul. Après avoir dit ça, quel moteur choisir ?
La liste est longue : Databricks (payant), Snowflake (payant), Microsoft Fabric (payant), MySQL (gratuit), PostgreSQL (gratuit) et ses extensions, Apache Druid (gratuit), Amazon Redshift (payant), Google BigQuery (payant), Apache Cassandra (gratuit), Apache HBase (gratuit), ClickHouse (gratuit), DuckDB (gratuit)… et tant d’autres.
EL et T
Historiquement, le processus ETL (Extract-Transform-Load) était le plus logique pour la transformation des Données, car les coûts de stockage, des calculs et de la bande passante étaient tous deux élevés. Transformer les données avant de les charger dans un data warehouse permettait de réduire ces deux coûts. Cependant, au cours de la dernière décennie, les data warehouses en cloud sont devenus omniprésents, réduisant les coûts de stockage et augmentant la puissance de traitement de manière exponentielle.
Le stockage des données brutes dans le data warehouse n’est donc plus une préoccupation majeure, et il est possible de transformer les données après leur chargement, plutôt qu’avant leur chargement. Connu sous le nom d’ELT (Extract-Load-Transform), ce processus de transformation des données après chargement présente un certain nombre d’avantages par rapport à l’ETL traditionnel.
L’une des principales différences entre l’ETL et l’ELT est l’endroit où les données brutes sont stockées :
Dans l’ETL, les données brutes restent stockées dans le système de production d’où elles proviennent. Ces dernières, copiées à partir de cette source de production, sont ensuite transformées d’un schéma normalisé en un schéma dimensionnel. Ainsi, les données chargées dans le système de destination ne sont plus les mêmes que les données brutes initialement copiées à partir du système de production.
Dans l’ELT, les données brutes du système de production sont copiées et chargées directement dans le système de destination avant d’être transformées. Ceci est important pour un certain nombre de raisons :
- Une source de données vérifiables : le fait que les données brutes soient stockées dans le système de destination constitue une source de données vérifiables. Il est parfois impossible de recharger les données brutes originales à partir du système de production parce qu’elles n’existent plus.
- Réduction du temps nécessaire à l’exploitation des données pour obtenir des informations : les professionnels peuvent exploiter les données brutes pour obtenir des informations supplémentaires au fur et à mesure des besoins, sans avoir à les recharger à chaque fois.
- Élimination de la nécessité de réapprovisionner les données : dans certains cas, si une transformation s’avère inadéquate, les données brutes devront être retransformées. Dans l’ETL, la source de données brutes doit d’abord être rechargée (en supposant qu’elle soit toujours disponible) dans le système secondaire, puis retransformée. Dans le cas de l’ELT, les données brutes sont stockées dans le système de destination, de sorte qu’il n’est pas nécessaire de les recharger et elles peuvent être transformées à nouveau immédiatement, représentant un gain de temps considérable.
- Temps de chargement plus rapide : comme l’ETL utilise un serveur de traitement et un système secondaire, le chargement des données dans le système de destination prend plus de temps. Avec l’ELT, le processus de chargement s’effectue directement des sources de données vers le système de destination.
- Des temps de transformation plus rapides : dans l’ETL, le temps de transformation est généralement plus lent et dépend de la taille de l’ensemble des données et de la puissance du serveur de flux. La transformation d’un grand ensemble de données peut prendre beaucoup de temps. Avec l’ELT, celle-ci est plus rapide, en particulier pour les grands ensembles de données, car elles sont chargées directement dans un système de destination et transformées en parallèle.
- Des délais d’exécution plus courts et moins de demandes de la part des ingénieurs : comme les analystes peuvent effectuer des transformations dans l’environnement du data warehouse sans avoir besoin de faire appel à des ingénieurs en données, les délais d’exécution de tous les projets d’analyse sont raccourcis, permettant d’obtenir plus rapidement des informations.
Pour ces différentes raisons le process est scindé en EL (Extract & Load) pour T (Transform).
L’orchestration
L’orchestration des flux de données est un processus essentiel : elle coordonne des tâches automatisées sur plusieurs systèmes, applications et services, créant des workflows de haut niveau. Elle permet de réunir des tâches unitaires, depuis la récupération des données dans les systèmes sources jusqu’à l’exposition de datasets préparés.
Dans une Modern Data Stack où la recherche d’automatisation par le re-use de traitements paramétrés et la notion de self-service sont très présentes, il faut obligatoirement un outil pour chapeauter l’ensemble.
Tout comme pour le compute, il existe de nombreux outils sur le marché : Apache Airflow (gratuit), Dagster (gratuit), Prefect (gratuit), Blueway (payant), Fivetran (payant), Matillion (payant), Microsoft Azure Data Factory (payant) ou des librairies Python comme dlt…
La gouvernance
Le dernier point, mais pas des moindres : la gouvernance de cet ensemble. Entre les data contracts, les data products, la qualité de la donnée et son suivi, le catalogage des assets data, le monitoring des pipelines, le besoin d’un outil englobant l’ensemble afin d’avoir un unique point of truth est indispensable.
C’est le point de rencontre entre data provider, data team et data consumer : l’exhaustivité et la complétude des metadatas (data contracts), autant des sources que des datasets mis à disposition, doivent se trouver dans cet outil pour être le socle de discussion entre métier et technique.
Plusieurs solutions existent, telles que Zeenea (payant), Datagalaxy (payant), Microsoft Purview (payant), Orkestra-datas (payant), Atlan (payant), Datahub Project (gratuit), Amundsen (gratuit), OpenMetaData (gratuit)…
Les solutions logiciels par couches

Deux grandes tendances apparaissent dans la Modern Data Stack : les solutions totalement intégrées, comme Microsoft Fabric, qui fournissent l’ensemble des outils dans une infrastructure déjà constituée, et les solutions best of breed, qui seront composées de différents outils à mettre en musique ensemble.
Chacune des solutions a ses avantages et inconvénients, et le choix dépendra de différents paramètres comme le coût global, les objectifs à court/moyen/long terme de la solution data, les compétences en interne pour développer les flux et dashboards, et administrer la data platform…
data-major est à même de vous accompagner dans cette prise de décision, en fonction de votre contexte technologique, financier et humain.
En conclusion
Construire une architecture de Modern Data Stack, c’est choisir des outils performants, mais aussi penser aux usages métiers, à la gouvernance et à l’évolutivité.
Ce n’est pas une recette figée, mais une combinaison ajustée selon le contexte de chaque entreprise.
👉 La technique seule ne suffit pas : c’est l’équilibre entre outils, normes et humains qui garantit le succès d’une démarche data-driven.

